Ziyang WangI am a fourth year CS Ph.D. student at The University of North Carolina, Chapel Hill advised by Prof. Mohit Bansal and also work closely with Prof. Gedas Bertasius. My research interest is video‐language understanding and multimodal AI. Particularly, I am interested in the challenge of reasoning over long and complex videos. I am actively looking for internship position for 2026 summer, feel free to reach out! Previously, I worked as a research intern at Salesforce in 2025 summer (manager: Dr. Juan Carlos Niebles). I worked as a research intern at Meta, FAIR Perception team in 2024 summer (managers: Dr. Ronghang Hu, and Dr. Christoph Feichtenhofer). Previously, I was an Applied Scientist Intern in Amazon Alexa AI working with Dr. Heba Elfardy, Dr. Kevin Small, Dr. Markus Dreyer. I also interned in Tsinghua AIR working with Prof. Jingjing Liu. I finished my undergrad study at UESTC and advised by Prof. Jingjing Li. My email address is ziyangw at cs . unc . edu, if you have any questions, feel free to contact me! Google Scholar / Curriculum Vitae / GitHub / Linkedin / Twitter |

|
ResearchIn general, I am interested in the fundamental challenges in video-language understanding. I have been working on multiple projects that aim to understand and reason over long and complex videos, including Agentic approach (VideoTree, CVPR 2025), RL + Test-time scaling (Video-RTS EMNLP 2025), LLM-based understanding (LLoVi, Mexa,... EMNLP 2024/2025) and coarse-to-fine alignments (UcoFiA ICCV2023). |
|
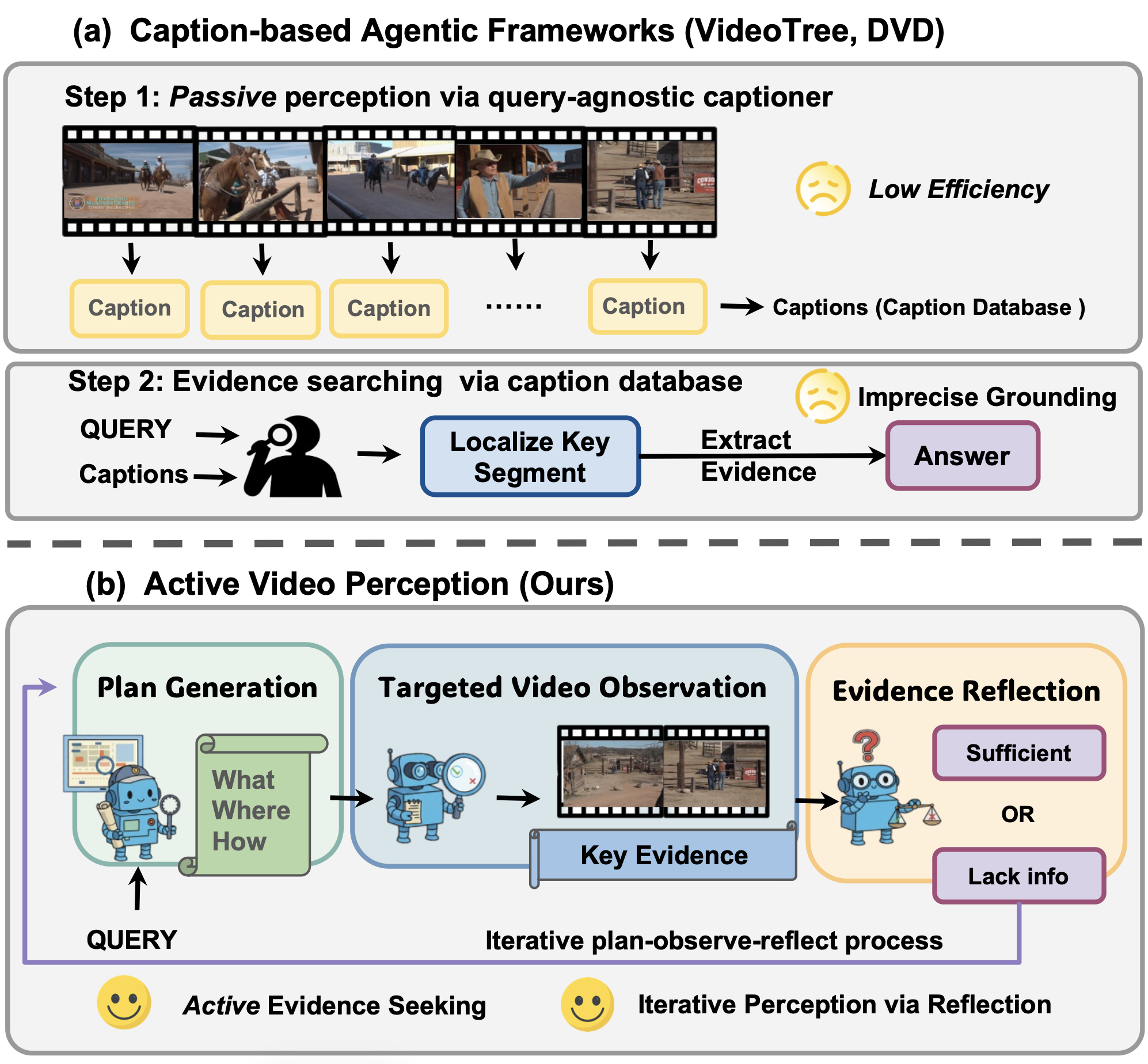
Active Video Perception: Iterative Evidence Seeking for Agentic Long Video UnderstandingZiyang Wang, Honglu Zhou, Shijie Wang, Junnan Li, Caiming Xiong, Silvio Savarese, Mohit Bansal, Michael S. Ryoo, Juan Carlos Niebles Arxiv arxiv / code / Inspired by active perception theory, we present Active Video Perception (AVP), which handles long video understanding as an iterative, query-driven evidence seeking process. Rather than passively caption the video frames, AVP treats the video as an interactive environment and actively decides what to inspect, where to focus, and at what granularity in order to acquire compact, time-stamped evidence directly from pixels. Concretely, AVP runs an iterative plan–observe–reflect process using MLLM agents. Empirically, AVP achieves best performance among agentic frameworks across five long video benchmarks, and surpasses the leading agentic method (DVD) by 5.7% in average accuracy while only requiring 18.4% inference time and 12.4% input tokens. |
|
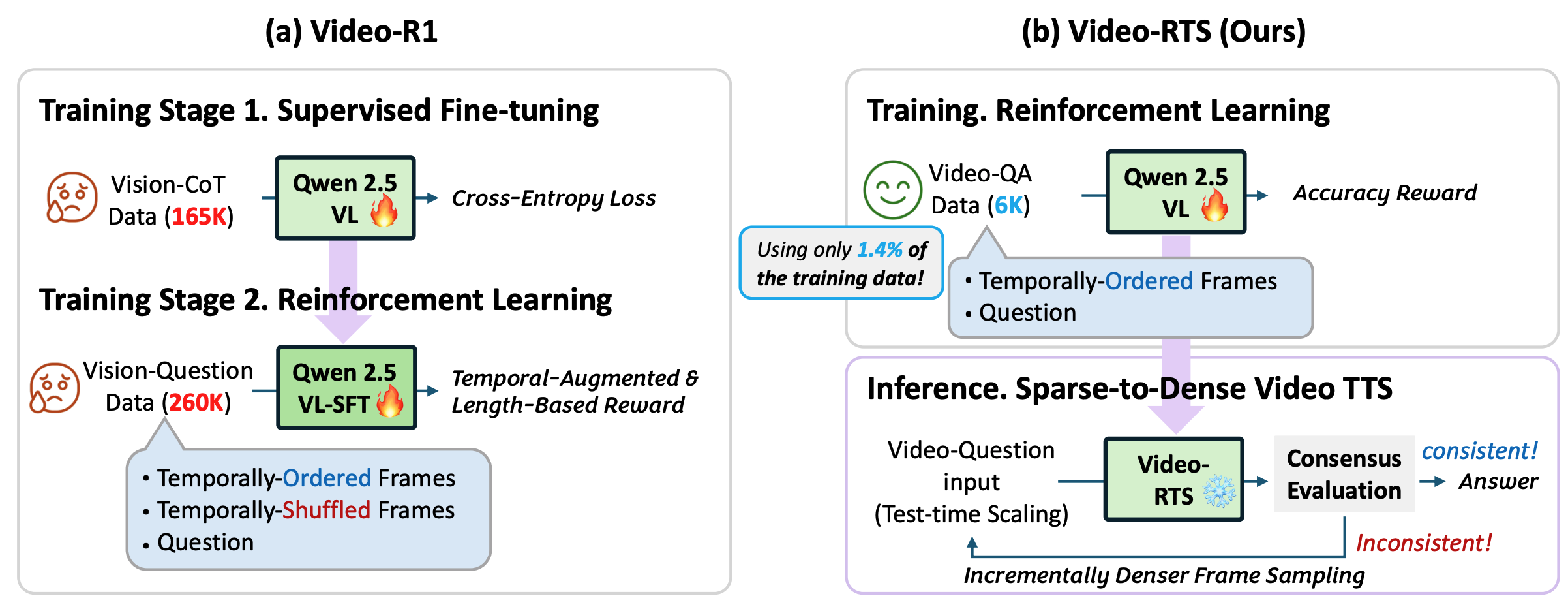
Video-RTS: Rethinking Reinforcement Learning and Test-Time Scaling for Efficient and Enhanced Video ReasoningZiyang Wang*,Jaehong Yoon*, Shoubin Yu, Md Mohaiminul Islam, Gedas Bertasius, Mohit Bansal EMNLP 2025 Main arxiv / code / We introduce Video-RTS, a new approach to improve video reasoning capability with drastically improved data efficiency by combining data-efficient RL with a video-adaptive test-time scaling (TTS) strategy. |
|
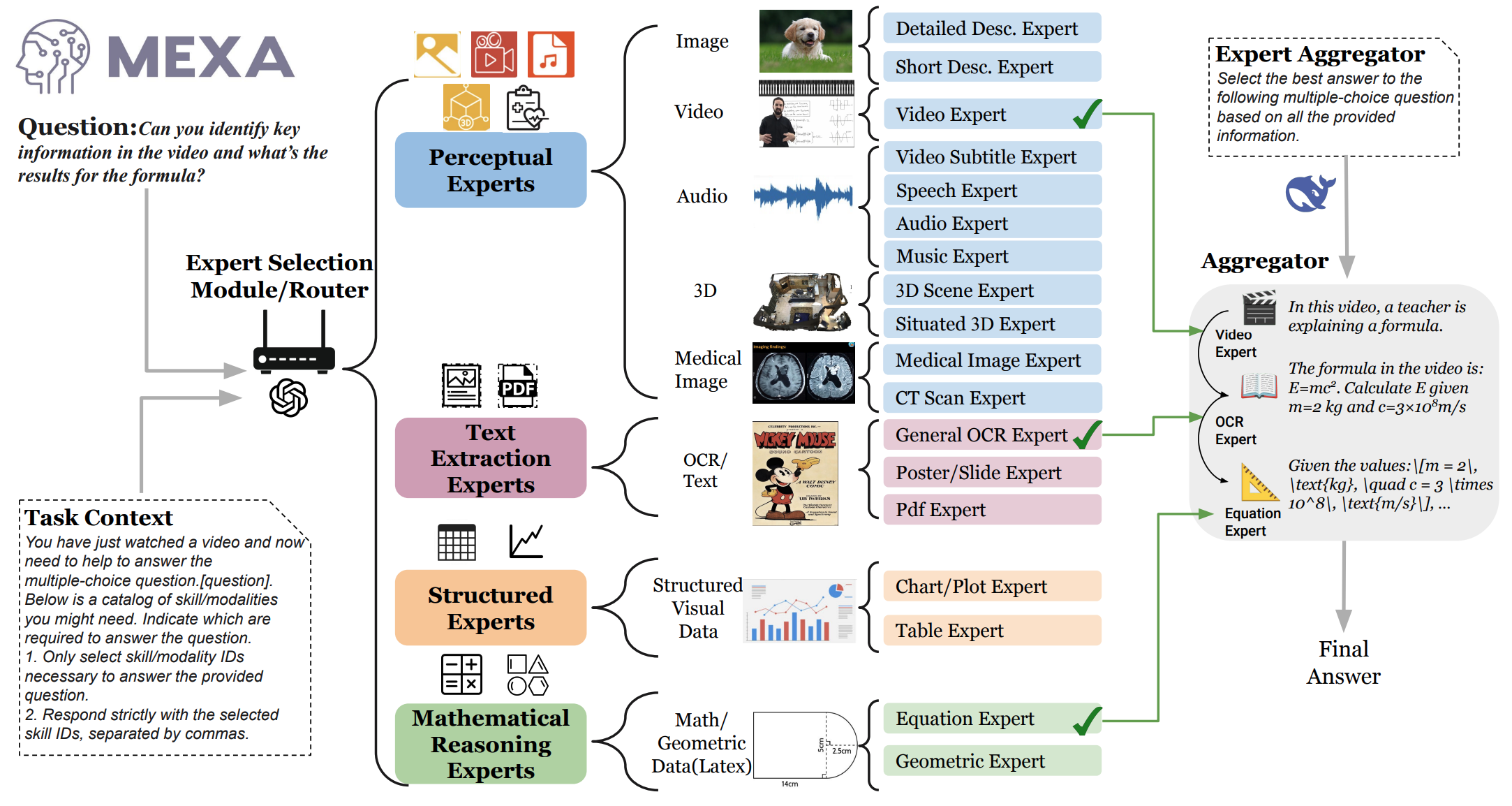
MEXA: Towards General Multimodal Reasoning with Dynamic Multi-Expert AggregationShoubin Yu*, Yue Zhang*, Ziyang Wang, Jaehong Yoon, Mohit Bansal EMNLP 2025 Findings arxiv / code / We introduce MEXA, a training-free framework that performs modality- and task-aware aggregation of multiple expert models to enable effective multimodal reasoning across diverse and distinct domains. |
|
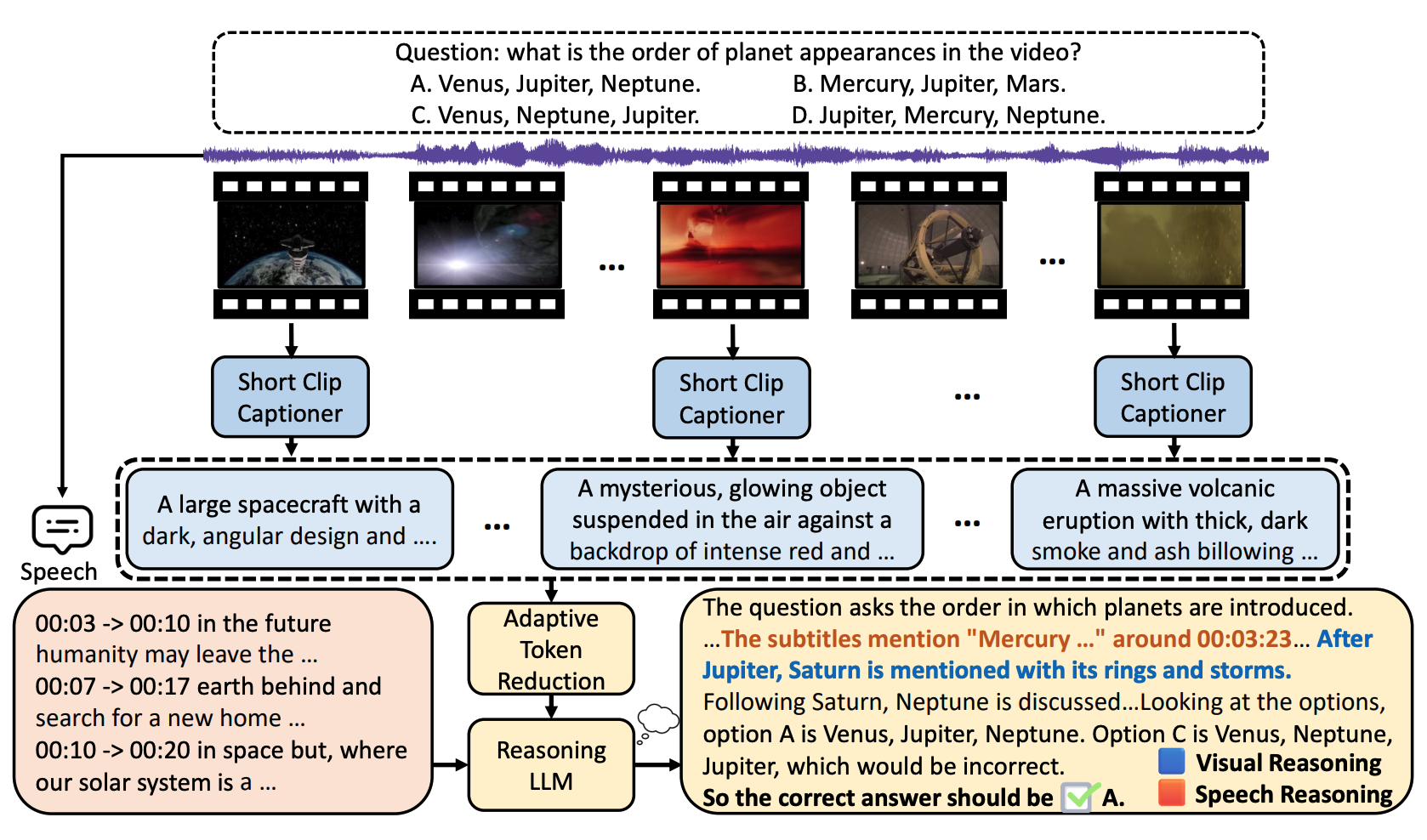
SiLVR: A Simple Language-based Video Reasoning FrameworkCe Zhang*, Yan-Bo Lin*, Ziyang Wang, Mohit Bansal, Gedas Bertasius Arxiv arxiv / code / We present SiLVR, a Simple Language-based Video Reasoning framework that decomposes complex video understanding into two stages. In the first stage, SiLVR transforms raw video into language-based representations using multisensory inputs, such as short clip captions and audio/speech subtitles. In the second stage, language descriptions are fed into a powerful reasoning LLM to solve complex video-language understanding tasks. SiLVR has been awarded the 1st in Track 1B: Multi-Discipline Lecture Understanding at CVPR 2025 Multimodal Video Agent Workshop |
|
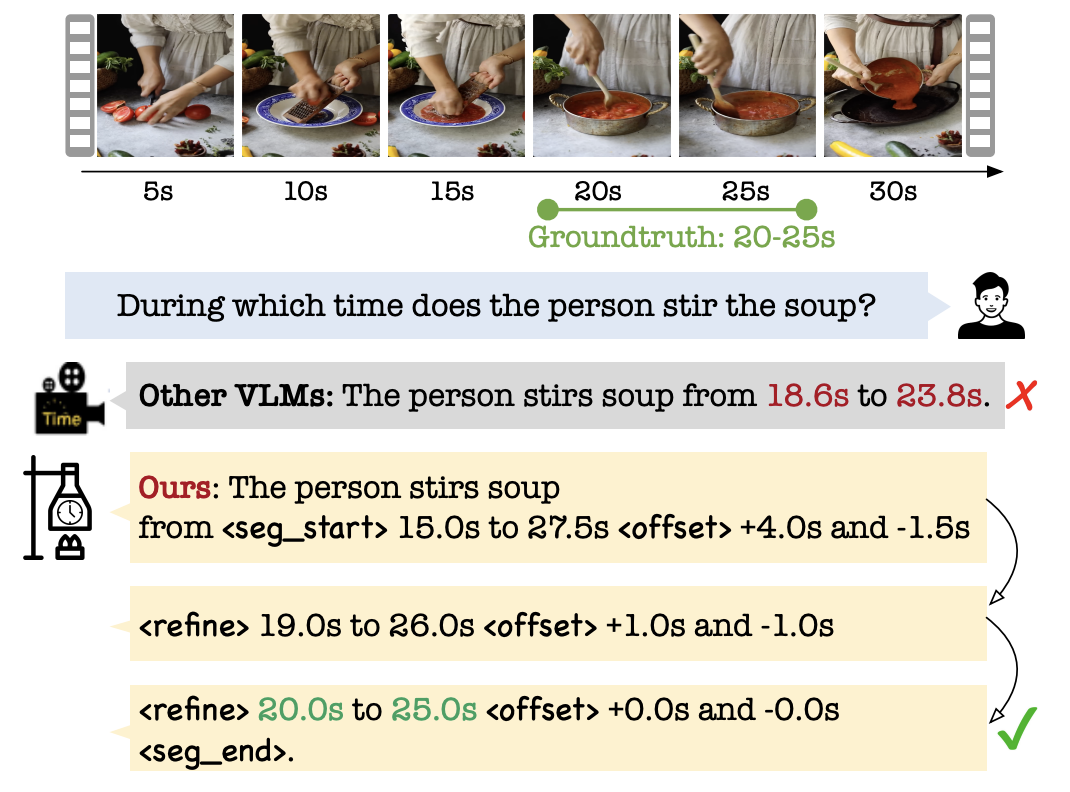
TimeRefine: Temporal Grounding with Time Refining Video LLMXizi Wang, Feng Cheng, Ziyang Wang, Huiyu Wang, Md Mohaiminul Islam, Lorenzo Torresani, Mohit Bansal, Gedas Bertasius, David Crandall WACV 2026 arxiv / In this work, we propose TimeRefine to enhance the capability of Video LLMs in performing temporal grounding. Unlike previous approaches that focus on data curation or architectural enhancements, we focus on refining the learning objective to better suit temporal grounding within the Video LLM framework. |
|
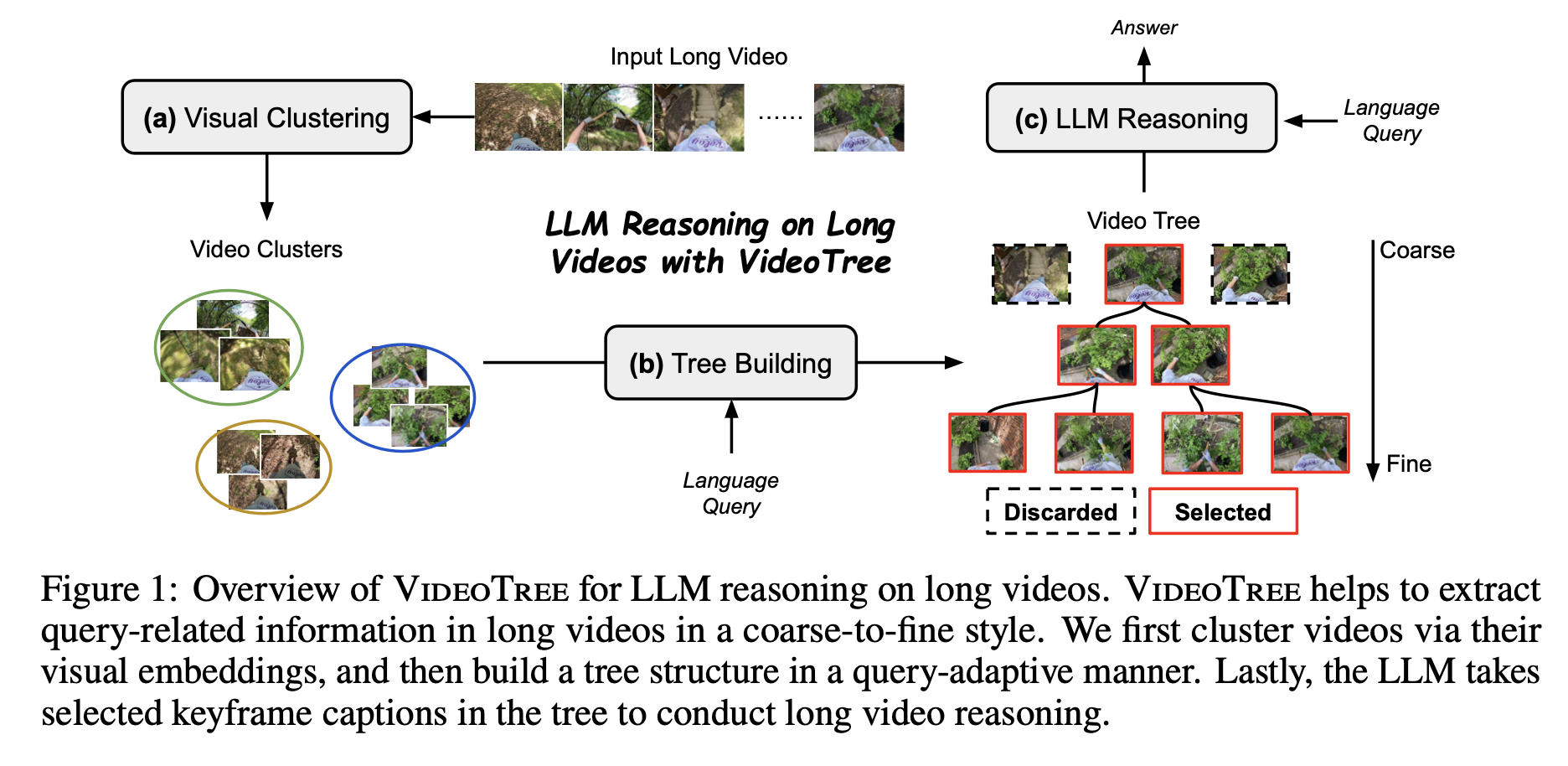
VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long VideosZiyang Wang*, Shoubin Yu*, Elias Stengel-Eskin*, Jaehong Yoon, Feng Cheng, Gedas Bertasius, Mohit Bansal CVPR 2025 arxiv / code / We introduce VideoTree, a query-adaptive and hierarchical framework for long-video understanding with LLMs. Specifically, VideoTree dynamically extracts query-related information from the input video and builds a tree-based video representation for LLM reasoning. |
|
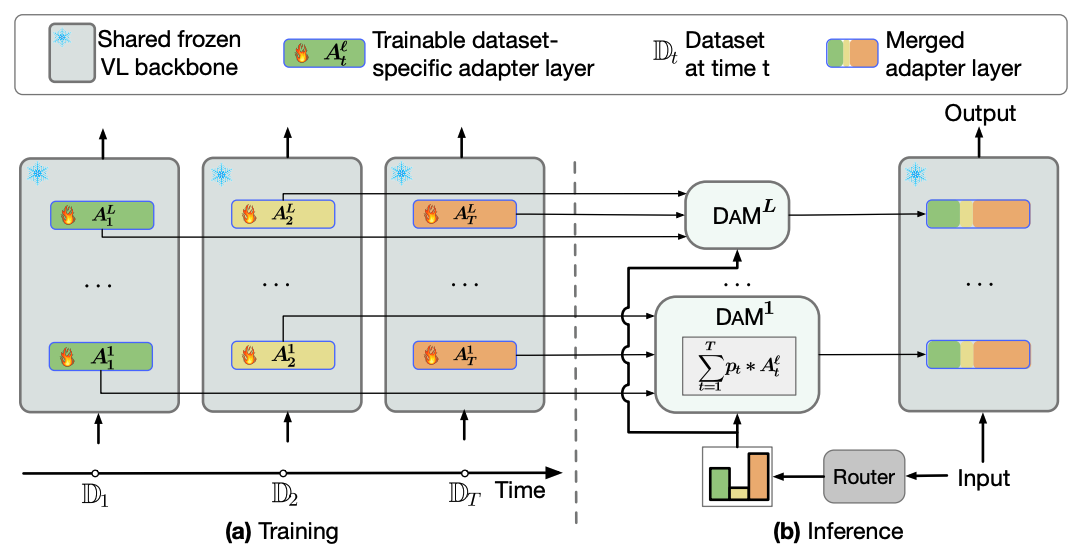
DAM: Dynamic Adapter Merging for Continual Video QA LearningFeng Cheng*, Ziyang Wang*, Yi-Lin Sung, Yan-Bo Lin, Mohit Bansal, Gedas Bertasius WACV 2025 arxiv / code / In this work, we investigate the challenging and relatively unexplored problem of rehearsal-free domain-incremental VidQA learning. Our proposed DAM framework outperforms existing state-of-the-art by 9.1% with 1.9% less forgetting on a benchmark with six distinct video domains. |
|
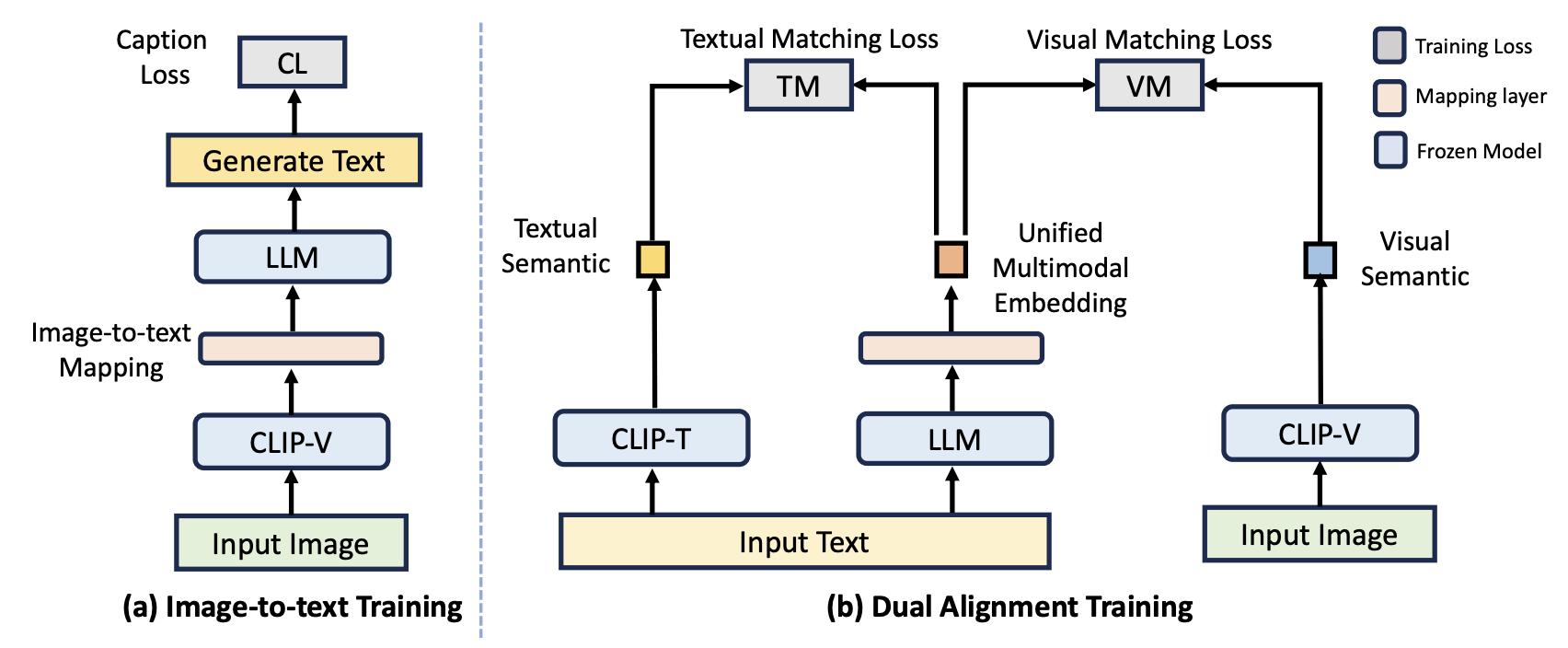
Unified Embeddings for Multimodal Retrieval via Frozen LLMsZiyang Wang, Heba Elfardy, Markus Dreyer, Kevin Small, Mohit Bansal EACL2024 Findings In this work, We present Unified Embeddings for Multimodal Retrieval (UNIMUR), a simple but effective approach that embeds multimodal inputs and retrieves visual and textual outputs via frozen Large Language Models (LLMs). Specifically, UNIMUR jointly retrieves multimodal outputs via unified multimodal embedding and applies dual alignment training to account for both visual and textual semantics. |
|
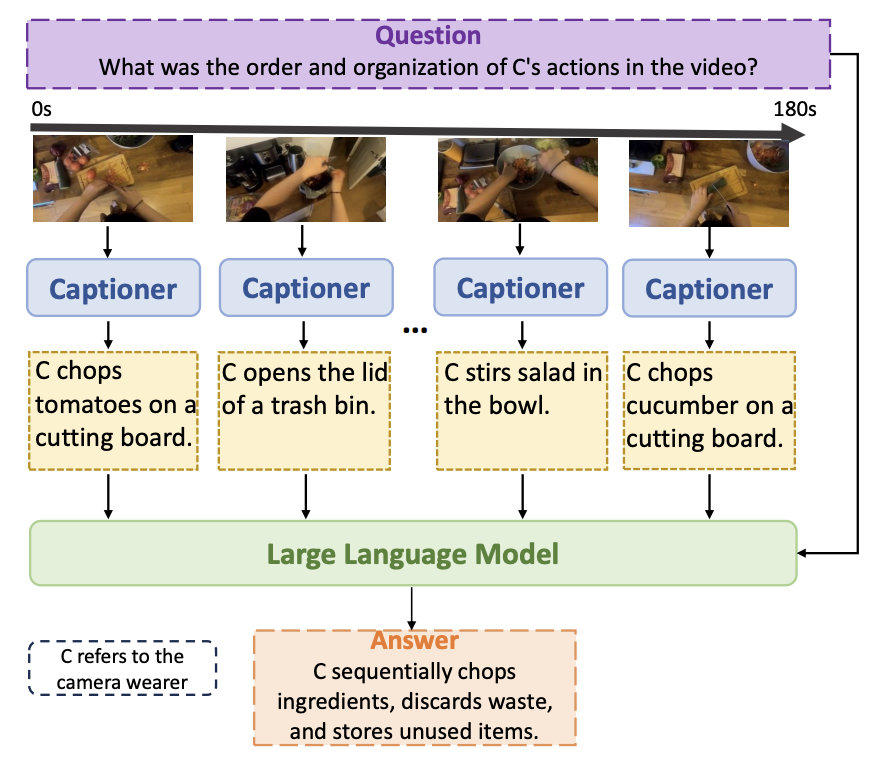
A Simple LLM Framework for Long-Range Video Question-AnsweringCe Zhang, Taixi Lu, Md Mohaiminul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, Gedas Bertasius EMNLP 2024 (main) arxiv / code / We present LLoVi, a language-based framework for long-range video question-answering (LVQA). Unlike prior long-range video understanding methods, which are often costly and require specialized long-range video modeling design (e.g., memory queues, state-space layers, etc.), our approach uses a frame/clip-level visual captioner coupled with a Large Language Model (GPT-3.5, GPT-4) leading to a simple yet surprisingly effective LVQA framework. |
|
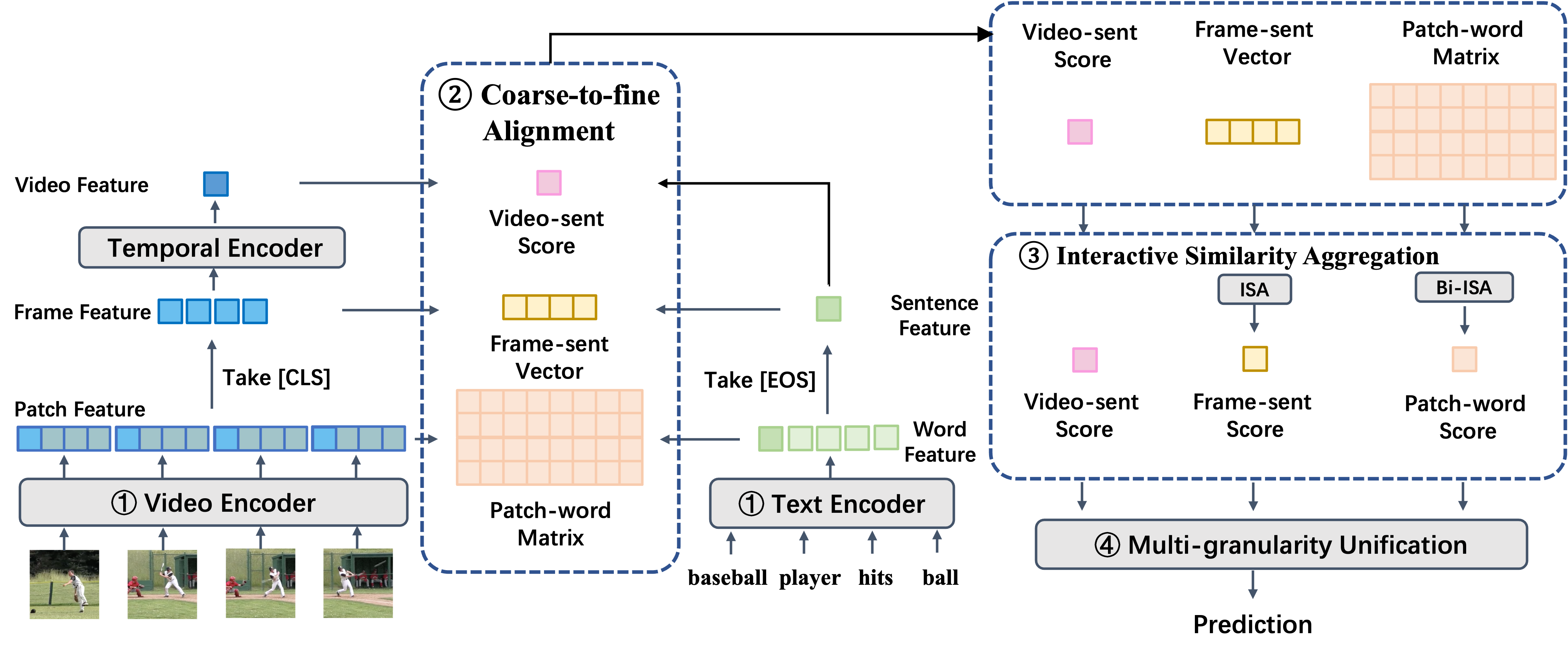
Unified Coarse-to-Fine Alignment for Video-Text RetrievalZiyang Wang, Yi-Lin Sung, Feng Cheng, Gedas Bertasius, Mohit Bansal ICCV23 arxiv / code / UCoFiA captures the cross-modal similarity information at different granularity levels(video-sentence, frame-sentence, pixel-word) and unifies multi-level alignments for video-text retrieval. |
|
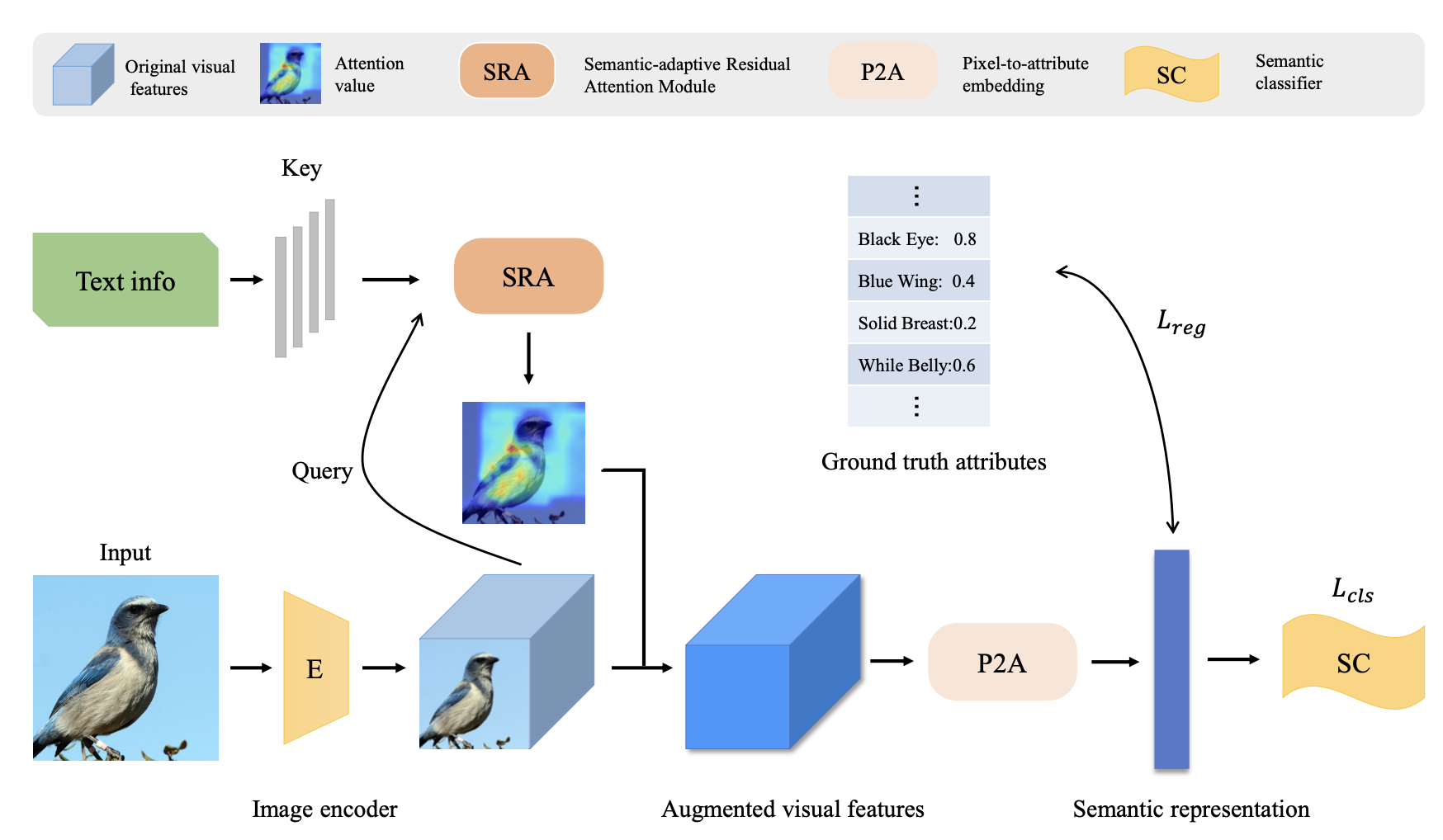
Language-Augmented Pixel Embedding for Generalized Zero-shot LearningZiyang Wang, Yunhao Gou, Jingjing Li, Lei Zhu, Heng Tao Shen IEEE Transactions on Circuits and Systems for Video Technology In this paper, we propose a novel GZSL framework named Language-Augmented Pixel Embedding (LAPE), which directly maps the image pixels to the semantic attributes with cross-modal guidance. |
|
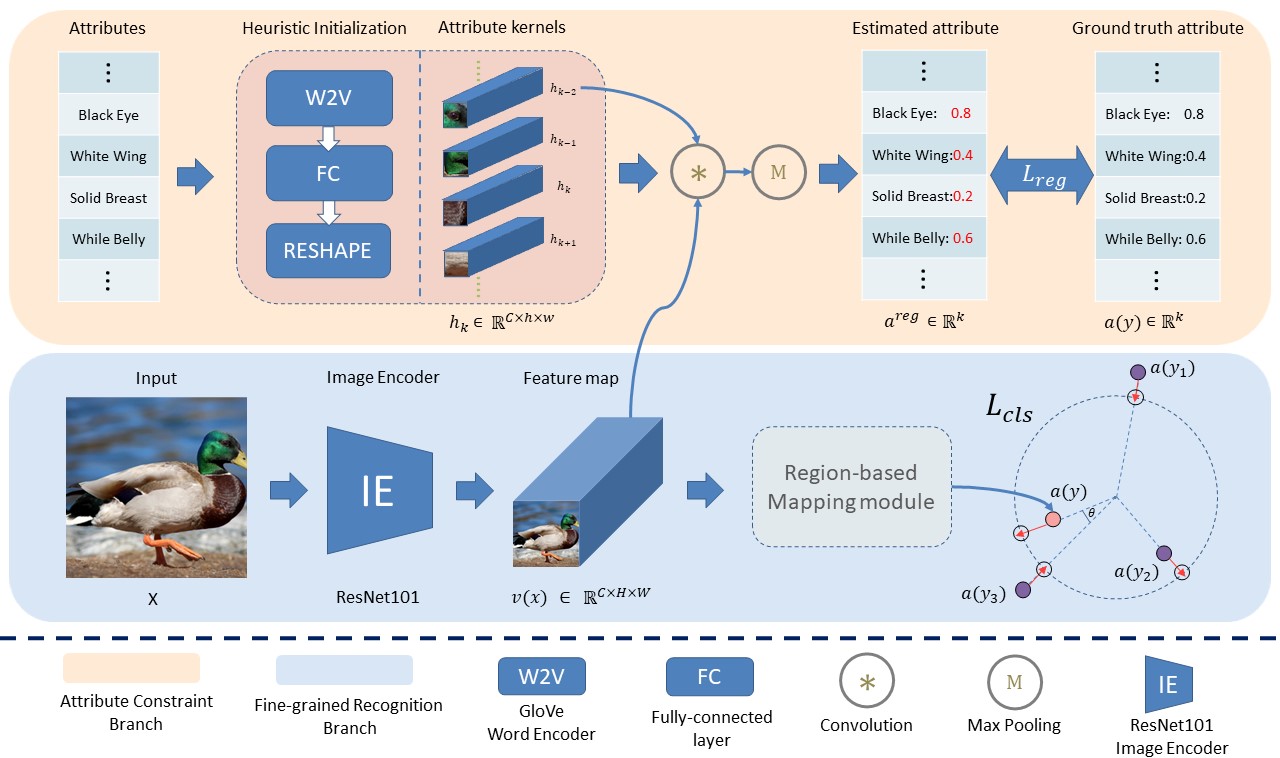
Region Semantically Aligned Network for Zero-Shot LearningZiyang Wang*, Yunhao Gou*, Jingjing Li, Yu Zhang, Yang Yang CIKM21 (long oral) arxiv / We propose a novel ZSL framework named Region Semantically Aligned Network (RSAN), which transfers region-attribute alignment from seen classes to unseen classes. |
HobbyI am a die-heart Arsenal and Tar Heel fan. |
|
Design and source code from Leonid Keselman's website, thanks! |